This just happened... 😨

Pending sector count increased to 3. I realized the drive is not part of the mergerFS array, but is used solely for backups. I recall this drive had some sector issue a few years ago that have then mysteriously disappeared. Anyways, started moving out the data from the drive and shopping for a set of new drives, maybe finally moving to ZFS
Regular BTRFS scrub of my OMV MergerFS array came up with this:
Scrub device /dev/sdb (id 1) done
Scrub started: Tue Apr 16 10:32:35 2024
Status: finished
Duration: 6:37:10
Total to scrub: 2.61TiB
Rate: 75.10MiB/s
Error summary: read=112
Corrected: 111
Uncorrectable: 1
Unverified: 0Running HDSentinel showed this:
HDD Device 1: /dev/sdb
HDD Model ID : WDC WD30EFRX-68EUZN0
HDD Serial No: WD-WMC4N1776822
HDD Revision : 80.00A80
HDD Size : 2861588 MB
Interface : SAT Standard USB/ATA
Temperature : 25 °C
Highest Temp.: 41 °C
Health : 99 %
Performance : 100 %
Power on time: 1374 days, 7 hours
Est. lifetime: more than 441 days
There are 1 weak sectors found on the disk surface. They may be remapped any time in the later use of the disk.
More information: https://www.hdsentinel.com/hard_disk_case_weak_sectors.php
At this point, warranty replacement of the disk is not yet possible, only if the health drops further.
It is recommended to examine the log of the disk regularly. All new problems found will be logged there.
No actions needed.Smartctl content is and the end of the post due to length and un-scrollability.
This is one of the oldest drives in my gear, acquired almost exactly 10 years ago (purchase date 30.3.2014) and running almost constantly at least since 2018 or so. Of course this just happens a week after missing one of the best deals for the past year for used enterprise harddrives. I should really begin to move out data from that disk. Will update if I ever did 😉
The pending sector count increased quite quickly to 3, so i moved all data out of the drive and started a repair job in HDSentinel under Windows.
The result it that the drive looks almost just like new:
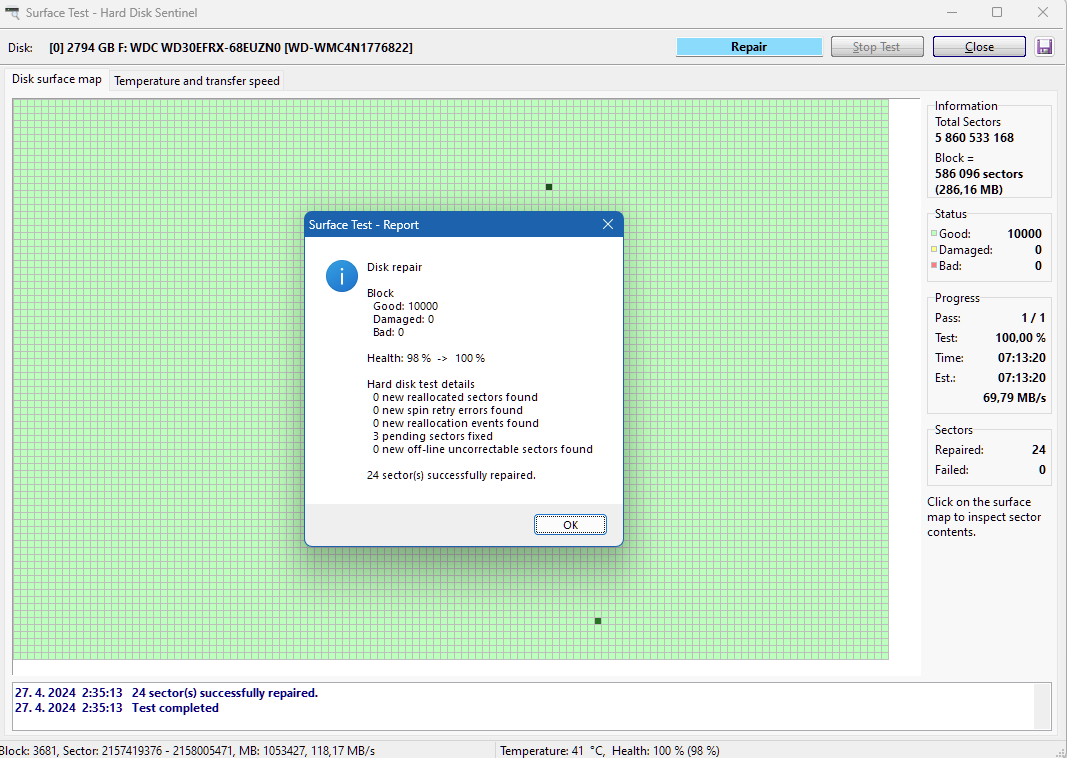
Weirdly I think the same thing happened a few years ago that was solved in the same way.
smartctl 7.3 2022-02-28 r5338 [x86_64-linux-6.5.13-5-pve] (local build)
Copyright (C) 2002-22, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Red (CMR)
Device Model: WDC WD30EFRX-68EUZN0
Serial Number: WD-WMC4N1776822
LU WWN Device Id: 5 0014ee 0591ad868
Firmware Version: 80.00A80
User Capacity: 3,000,592,982,016 bytes [3.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5400 rpm
Device is: In smartctl database 7.3/5610
ATA Version is: ACS-2 (minor revision not indicated)
SATA Version is: SATA 3.0, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Wed Apr 17 22:49:10 2024 CEST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
AAM feature is: Unavailable
APM feature is: Unavailable
Rd look-ahead is: Enabled
Write cache is: Enabled
DSN feature is: Unavailable
ATA Security is: Disabled, NOT FROZEN [SEC1]
Wt Cache Reorder: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x00) Offline data collection activity
was never started.
Auto Offline Data Collection: Disabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: (39720) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 399) minutes.
Conveyance self-test routine
recommended polling time: ( 5) minutes.
SCT capabilities: (0x703d) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
1 Raw_Read_Error_Rate POSR-K 200 200 051 - 28
3 Spin_Up_Time POS--K 178 173 021 - 6058
4 Start_Stop_Count -O--CK 099 099 000 - 1332
5 Reallocated_Sector_Ct PO--CK 200 200 140 - 0
7 Seek_Error_Rate -OSR-K 200 200 000 - 0
9 Power_On_Hours -O--CK 055 055 000 - 32983
10 Spin_Retry_Count -O--CK 100 100 000 - 0
11 Calibration_Retry_Count -O--CK 100 100 000 - 0
12 Power_Cycle_Count -O--CK 100 100 000 - 446
192 Power-Off_Retract_Count -O--CK 200 200 000 - 78
193 Load_Cycle_Count -O--CK 198 198 000 - 6585
194 Temperature_Celsius -O---K 125 109 000 - 25
196 Reallocated_Event_Count -O--CK 200 200 000 - 0
197 Current_Pending_Sector -O--CK 200 200 000 - 1
198 Offline_Uncorrectable ----CK 100 253 000 - 0
199 UDMA_CRC_Error_Count -O--CK 200 200 000 - 0
200 Multi_Zone_Error_Rate ---R-- 100 253 000 - 0
||||||_ K auto-keep
|||||__ C event count
||||___ R error rate
|||____ S speed/performance
||_____ O updated online
|______ P prefailure warning
General Purpose Log Directory Version 1
SMART Log Directory Version 1 [multi-sector log support]
Address Access R/W Size Description
0x00 GPL,SL R/O 1 Log Directory
0x01 SL R/O 1 Summary SMART error log
0x02 SL R/O 5 Comprehensive SMART error log
0x03 GPL R/O 6 Ext. Comprehensive SMART error log
0x06 SL R/O 1 SMART self-test log
0x07 GPL R/O 1 Extended self-test log
0x09 SL R/W 1 Selective self-test log
0x10 GPL R/O 1 NCQ Command Error log
0x11 GPL R/O 1 SATA Phy Event Counters log
0x21 GPL R/O 1 Write stream error log
0x22 GPL R/O 1 Read stream error log
0x80-0x9f GPL,SL R/W 16 Host vendor specific log
0xa0-0xa7 GPL,SL VS 16 Device vendor specific log
0xa8-0xb7 GPL,SL VS 1 Device vendor specific log
0xbd GPL,SL VS 1 Device vendor specific log
0xc0 GPL,SL VS 1 Device vendor specific log
0xc1 GPL VS 93 Device vendor specific log
0xe0 GPL,SL R/W 1 SCT Command/Status
0xe1 GPL,SL R/W 1 SCT Data Transfer
SMART Extended Comprehensive Error Log Version: 1 (6 sectors)
Device Error Count: 32 (device log contains only the most recent 24 errors)
CR = Command Register
FEATR = Features Register
COUNT = Count (was: Sector Count) Register
LBA_48 = Upper bytes of LBA High/Mid/Low Registers ] ATA-8
LH = LBA High (was: Cylinder High) Register ] LBA
LM = LBA Mid (was: Cylinder Low) Register ] Register
LL = LBA Low (was: Sector Number) Register ]
DV = Device (was: Device/Head) Register
DC = Device Control Register
ER = Error register
ST = Status register
Powered_Up_Time is measured from power on, and printed as
DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes,
SS=sec, and sss=millisec. It "wraps" after 49.710 days.
Error 32 [7] occurred at disk power-on lifetime: 32953 hours (1373 days + 1 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER -- ST COUNT LBA_48 LH LM LL DV DC
-- -- -- == -- == == == -- -- -- -- --
40 -- 51 00 00 00 01 46 0b cc f8 40 00 Error: UNC at LBA = 0x1460bccf8 = 5470145784
Commands leading to the command that caused the error were:
CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name
-- == -- == -- == == == -- -- -- -- -- --------------- --------------------
60 00 08 00 00 00 01 46 0b cc f8 40 00 28d+18:41:39.695 READ FPDMA QUEUED
60 00 08 00 00 00 01 46 0b cc f0 40 00 28d+18:41:39.695 READ FPDMA QUEUED
60 00 08 00 00 00 01 46 0b cc e8 40 00 28d+18:41:39.694 READ FPDMA QUEUED
60 00 08 00 00 00 01 46 0b cc e0 40 00 28d+18:41:39.694 READ FPDMA QUEUED
60 00 08 00 00 00 01 46 0b cc d8 40 00 28d+18:41:39.694 READ FPDMA QUEUED
Error 31 [6] occurred at disk power-on lifetime: 32953 hours (1373 days + 1 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER -- ST COUNT LBA_48 LH LM LL DV DC
-- -- -- == -- == == == -- -- -- -- --
40 -- 51 00 c0 00 01 46 0b cc f8 40 00 Error: UNC at LBA = 0x1460bccf8 = 5470145784
Commands leading to the command that caused the error were:
CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name
-- == -- == -- == == == -- -- -- -- -- --------------- --------------------
60 04 00 00 58 00 01 46 0b e4 00 40 00 28d+18:41:36.065 READ FPDMA QUEUED
60 04 00 00 50 00 01 46 0b e0 00 40 00 28d+18:41:36.065 READ FPDMA QUEUED
60 04 00 00 48 00 01 46 0b dc 00 40 00 28d+18:41:36.064 READ FPDMA QUEUED
60 04 00 00 40 00 01 46 0b d8 00 40 00 28d+18:41:36.064 READ FPDMA QUEUED
60 04 00 00 18 00 01 46 0b d4 00 40 00 28d+18:41:36.064 READ FPDMA QUEUED
Error 30 [5] occurred at disk power-on lifetime: 25310 hours (1054 days + 14 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER -- ST COUNT LBA_48 LH LM LL DV DC
-- -- -- == -- == == == -- -- -- -- --
40 -- 51 00 00 00 01 50 f9 04 67 40 00 Error: UNC at LBA = 0x150f90467 = 5653464167
Commands leading to the command that caused the error were:
CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name
-- == -- == -- == == == -- -- -- -- -- --------------- --------------------
60 00 01 00 38 00 01 50 f9 04 67 40 00 06:50:41.775 READ FPDMA QUEUED
2f 00 00 00 01 00 00 00 00 00 10 e0 00 06:50:41.473 READ LOG EXT
60 00 01 00 30 00 01 50 f9 04 67 40 00 06:50:41.311 READ FPDMA QUEUED
2f 00 00 00 01 00 00 00 00 00 10 e0 00 06:50:41.007 READ LOG EXT
60 00 01 00 28 00 01 50 f9 04 67 40 00 06:50:40.772 READ FPDMA QUEUED
Error 29 [4] occurred at disk power-on lifetime: 25310 hours (1054 days + 14 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER -- ST COUNT LBA_48 LH LM LL DV DC
-- -- -- == -- == == == -- -- -- -- --
40 -- 51 00 00 00 01 50 f9 04 67 40 00 Error: UNC at LBA = 0x150f90467 = 5653464167
Commands leading to the command that caused the error were:
CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name
-- == -- == -- == == == -- -- -- -- -- --------------- --------------------
60 00 01 00 30 00 01 50 f9 04 67 40 00 06:50:41.311 READ FPDMA QUEUED
2f 00 00 00 01 00 00 00 00 00 10 e0 00 06:50:41.007 READ LOG EXT
60 00 01 00 28 00 01 50 f9 04 67 40 00 06:50:40.772 READ FPDMA QUEUED
61 00 01 00 20 00 01 50 f9 04 66 40 00 06:50:40.767 WRITE FPDMA QUEUED
61 00 01 00 18 00 01 50 f9 04 66 40 00 06:50:40.767 WRITE FPDMA QUEUED
Error 28 [3] occurred at disk power-on lifetime: 25310 hours (1054 days + 14 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER -- ST COUNT LBA_48 LH LM LL DV DC
-- -- -- == -- == == == -- -- -- -- --
40 -- 51 00 00 00 01 50 f9 04 67 40 00 Error: UNC at LBA = 0x150f90467 = 5653464167
Commands leading to the command that caused the error were:
CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name
-- == -- == -- == == == -- -- -- -- -- --------------- --------------------
60 00 01 00 28 00 01 50 f9 04 67 40 00 06:50:40.772 READ FPDMA QUEUED
61 00 01 00 20 00 01 50 f9 04 66 40 00 06:50:40.767 WRITE FPDMA QUEUED
61 00 01 00 18 00 01 50 f9 04 66 40 00 06:50:40.767 WRITE FPDMA QUEUED
61 00 01 00 10 00 01 50 f9 04 66 40 00 06:50:40.767 WRITE FPDMA QUEUED
61 00 01 00 08 00 01 50 f9 04 66 40 00 06:50:40.767 WRITE FPDMA QUEUED
Error 27 [2] occurred at disk power-on lifetime: 25310 hours (1054 days + 14 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER -- ST COUNT LBA_48 LH LM LL DV DC
-- -- -- == -- == == == -- -- -- -- --
40 -- 51 00 00 00 01 50 f9 04 66 40 00 Error: UNC at LBA = 0x150f90466 = 5653464166
Commands leading to the command that caused the error were:
CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name
-- == -- == -- == == == -- -- -- -- -- --------------- --------------------
60 00 01 00 f0 00 01 50 f9 04 66 40 00 06:50:40.301 READ FPDMA QUEUED
2f 00 00 00 01 00 00 00 00 00 10 e0 00 06:50:39.997 READ LOG EXT
60 00 01 00 e8 00 01 50 f9 04 66 40 00 06:50:39.834 READ FPDMA QUEUED
2f 00 00 00 01 00 00 00 00 00 10 e0 00 06:50:39.531 READ LOG EXT
60 00 01 00 e0 00 01 50 f9 04 66 40 00 06:50:39.364 READ FPDMA QUEUED
Error 26 [1] occurred at disk power-on lifetime: 25310 hours (1054 days + 14 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER -- ST COUNT LBA_48 LH LM LL DV DC
-- -- -- == -- == == == -- -- -- -- --
40 -- 51 00 00 00 01 50 f9 04 66 40 00 Error: UNC at LBA = 0x150f90466 = 5653464166
Commands leading to the command that caused the error were:
CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name
-- == -- == -- == == == -- -- -- -- -- --------------- --------------------
60 00 01 00 e8 00 01 50 f9 04 66 40 00 06:50:39.834 READ FPDMA QUEUED
2f 00 00 00 01 00 00 00 00 00 10 e0 00 06:50:39.531 READ LOG EXT
60 00 01 00 e0 00 01 50 f9 04 66 40 00 06:50:39.364 READ FPDMA QUEUED
61 00 01 00 d8 00 01 50 f9 04 65 40 00 06:50:39.358 WRITE FPDMA QUEUED
61 00 01 00 d0 00 01 50 f9 04 65 40 00 06:50:39.358 WRITE FPDMA QUEUED
Error 25 [0] occurred at disk power-on lifetime: 25310 hours (1054 days + 14 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER -- ST COUNT LBA_48 LH LM LL DV DC
-- -- -- == -- == == == -- -- -- -- --
40 -- 51 00 00 00 01 50 f9 04 66 40 00 Error: UNC at LBA = 0x150f90466 = 5653464166
Commands leading to the command that caused the error were:
CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name
-- == -- == -- == == == -- -- -- -- -- --------------- --------------------
60 00 01 00 e0 00 01 50 f9 04 66 40 00 06:50:39.364 READ FPDMA QUEUED
61 00 01 00 d8 00 01 50 f9 04 65 40 00 06:50:39.358 WRITE FPDMA QUEUED
61 00 01 00 d0 00 01 50 f9 04 65 40 00 06:50:39.358 WRITE FPDMA QUEUED
61 00 01 00 c8 00 01 50 f9 04 65 40 00 06:50:39.358 WRITE FPDMA QUEUED
61 00 01 00 c0 00 01 50 f9 04 65 40 00 06:50:39.358 WRITE FPDMA QUEUED
SMART Extended Self-test Log Version: 1 (1 sectors)
No self-tests have been logged. [To run self-tests, use: smartctl -t]
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.
SCT Status Version: 3
SCT Version (vendor specific): 258 (0x0102)
Device State: Stand-by (1)
Current Temperature: 25 Celsius
Power Cycle Min/Max Temperature: 23/31 Celsius
Lifetime Min/Max Temperature: 12/41 Celsius
Under/Over Temperature Limit Count: 0/0
Vendor specific:
01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
SCT Temperature History Version: 2
Temperature Sampling Period: 1 minute
Temperature Logging Interval: 1 minute
Min/Max recommended Temperature: 0/60 Celsius
Min/Max Temperature Limit: -41/85 Celsius
Temperature History Size (Index): 478 (177)
Index Estimated Time Temperature Celsius
178 2024-04-17 14:52 27 ********
... ..( 58 skipped). .. ********
237 2024-04-17 15:51 27 ********
238 2024-04-17 15:52 26 *******
... ..( 2 skipped). .. *******
241 2024-04-17 15:55 26 *******
242 2024-04-17 15:56 25 ******
243 2024-04-17 15:57 25 ******
244 2024-04-17 15:58 24 *****
... ..(357 skipped). .. *****
124 2024-04-17 21:56 24 *****
125 2024-04-17 21:57 ? -
126 2024-04-17 21:58 24 *****
... ..( 4 skipped). .. *****
131 2024-04-17 22:03 24 *****
132 2024-04-17 22:04 25 ******
... ..( 3 skipped). .. ******
136 2024-04-17 22:08 25 ******
137 2024-04-17 22:09 26 *******
... ..( 13 skipped). .. *******
151 2024-04-17 22:23 26 *******
152 2024-04-17 22:24 27 ********
... ..( 24 skipped). .. ********
177 2024-04-17 22:49 27 ********
SCT Error Recovery Control:
Read: 70 (7.0 seconds)
Write: 70 (7.0 seconds)
Device Statistics (GP/SMART Log 0x04) not supported
Pending Defects log (GP Log 0x0c) not supported
SATA Phy Event Counters (GP Log 0x11)
ID Size Value Description
0x0001 2 0 Command failed due to ICRC error
0x0002 2 0 R_ERR response for data FIS
0x0003 2 0 R_ERR response for device-to-host data FIS
0x0004 2 0 R_ERR response for host-to-device data FIS
0x0005 2 0 R_ERR response for non-data FIS
0x0006 2 0 R_ERR response for device-to-host non-data FIS
0x0007 2 0 R_ERR response for host-to-device non-data FIS
0x0008 2 0 Device-to-host non-data FIS retries
0x0009 2 11 Transition from drive PhyRdy to drive PhyNRdy
0x000a 2 12 Device-to-host register FISes sent due to a COMRESET
0x000b 2 0 CRC errors within host-to-device FIS
0x000f 2 0 R_ERR response for host-to-device data FIS, CRC
0x0012 2 0 R_ERR response for host-to-device non-data FIS, CRC
0x8000 4 2594442 Vendor specific
Comments ()